PyTorch를 TPU에서 사용해보기 (1)
Updated:
처음에 머신러닝으로 공부를 시작했을 때는 하드웨어의 필요성에 대한 생각이 별로 없었는데, 최근에는 거의 딥러닝 모델만을 다루다보니 하드웨어에 대한 욕심이 점점 생기기 시작했다. 그리고 회사에 있을 때 다수의 DGX-1 서버를 사용하면서 많은 GPU를 사용할 수 있는 환경에서 실험을 해보고나니 더 욕심이 생기는 것 같다. 그런데 이제 다시 학생이라 GPU를 새로 살 돈은 없고… 그래서 무료로 사용할 수 있는 Google Colaboratory에 대해 찾아보고 있다.
일단 개인적으로 Colab의 가장 큰 단점은 무료 버전의 경우 12시간만 세션을 유지할 수 있다는 것이라고 생각한다. (유료 버전의 경우 24시간 동안 세션 유지) 기본 colab에 새로운 파이썬 패키지들을 깔더라도 12시간(또는 24시간)이 지나면 세션이 리셋이 되기 때문에 다시 설치해줘야 하는 단점이 있다. 하지만 아직까지는 12시간 넘게 모델을 돌릴 경우가 없기도 하고, 혹시 12시간을 넘기더라도 체크 포인트 등을 저장해서 이어서 하면 될 것 같다는 생각이 든다. 그리고 오류인지는 모르겠지만 가끔 "Failed to assign a backend"와 같이 Resource가 부족하면 연결이 안 되는 것 같다. 그래도 무엇보다 GPU나 TPU를 무료로 쓸 수 있다는 장점이 이러한 단점들을 이길 수 있다고 생각한다. 그래서 google colab에서 GPU와 TPU를 사용하는 방법을 공부했던 과정을 적어보려 한다.
1. AI 가속기(GPU, TPU 등)의 필요성
GPU와 TPU를 통틀어서 뭐라고 표현하는지 찾아보다가 AI 가속기라는 단어가 많이 보인다. TPU(Tensor Processing Unit)는 Google에서 애초에 뉴럴 네트워크 계산용으로 만든 것이라 적절하다고 생각한다. 하지만 GPU는 AI 계산용으로만 만들어진 것은 아니기 때문에 AI 가속기라 부르는 것이 적절한가 의문이 있었지만 사용 용도에 따라 AI 가속기라는 단어도 적절할 수 있다고 생각한다.
개인적으로 생각했을 때 좋은 하드웨어 성능을 필요로 하는 경우는 다음의 정도일 것이다.
- 빠른 속도로 딥러닝 모델을 학습하고 싶은 경우
- 엄청 큰 딥러닝 모델을 사용하기 때문에 하나의 GPU에 한번에 못 올리는 경우(Model parallel)
- 적당한 모델을 사용하지만 한 번에 많은 데이터를 학습하고 싶은 경우(Data parallel)
두, 세 번째 경우는 한 번에 큰 모델 또는 많은 데이터를 처리하는 문제로 AI 가속기의 메모리와 관련된 부분이다. 메모리에는 아직까지 어느 정도의 한계가 있다고 생각한다. 물론, 엄청 비싼 AI 가속기를 쓰면 더 큰 메모리를 사용할 수 있겠지만 일반적으로 많은 사람들이 사용하는 Nvidia의 Titan, GTX, RTX 등의 계열에서는 메모리의 한계가 있다고 생각한다. 그리고 다수의 AI 가속기와 딥러닝 프레임워크(TensorFlow, PyTorch 등)의 Model/Data parallelism 방법을 이용하면 해결 가능한 문제라고 생각한다. 본 포스팅에서는 AI 가속기를 단순히 빠른 계산을 위해서만 사용하는 것에 목적을 두고 있어 메모리와 관련된 부분은 다루지 않는다.
딥러닝을 공부하다보면 조금 더 좋은 성능을 위해 Hyper parameter들을 다양하게 튜닝해보고 싶을 때가 있다. 요즘에는 Hyper parameter들을 자동으로 튜닝해주는 툴들이 있지만, 공부하고 있는 학생의 입장에서 그런 툴들을 사용하는 것이 뭔가 반칙을 쓰는 것 같은 생각도 들고 Hyper parameter들을 직접 튜닝하면서 얻는 경험들을 포기하는 것 같아 되도록 직접 튜닝을 하려고 하고 있다. 하지만 Hyper parameter 튜닝 과정은 굉장히 지루하다. 개인적으로, 큰 모델의 경우 학습이 오래 걸려서 지루하고 작은 모델의 경우 학습이 금방 되지만 더 다양한 조합으로 튜닝 해보고 싶은 욕심이 생겨서 많이 돌려보느라 지루하다. 하지만 느려서 몇 번 튜닝을 못 해보는 것 보다는 빠르게 많이 돌려보는 것을 더 선호해서 빠른 AI 가속기를 찾게 되었다. GPU는 많이 써봤지만 TPU는 Google에서 자체 제작해서 사용하던 것으로 알고 있는데 colab을 통해 사용할 수 있다고 하여 얼마나 빠른지 경험해보고 싶었다.
1.1. TPU? GPU?
TPU를 사용해보기 전에 TPU가 무엇인지 GPU와 어떤 차이가 있는지 간단히 찾아보고 싶었다. 아래의 내용과 그림 등은 Google Cloud TPU 초보자 가이드를 참고하였다. GPU가 어떻게 작동하고 왜 CPU보다 계산이 빠른지 컨퍼런스나 강의 등에서 몇 번 들은 적은 있지만 컴퓨터 공학과 출신이 아닌 나로써는 제대로 이해한 적이 없다. 컴퓨터 공학을 전공하면 CPU, GPU 구조에 대해서 배우는지는 잘 모르겠다. 물론 지금도 제대로 이해하고 내용을 쓰고 있지는 않다. 또한, TPU와 GPU의 가장 큰 차이(?)는 GPU는 보통 32비트 연산을 이용하지만 TPU는 8비트 연산을 이용한다는 것 같다. 1세대 TPU가 8 비트 연산기를 이용하고 2세대 TPU에서는 16비트 연산기를 사용했다고 한다.
TPU: 딥러닝 학습은 대규모 데이터세트를 반복적으로 처리하는 경우가 많은데, Google은 이러한 대규모 연산 작업 부하를 몇 주가 아닌 몇 분 내지 몇 시간 만에 완료할 수 있도록 하여 생산성을 높이기 위해 TPU를 설계하고 개발하였다.
1.1.1. CPU 작동 원리
 cpu 작동 원리
cpu 작동 원리
CPU의 가장 큰 장점은 유연성이라고 한다. 즉, CPU를 이용하여 문서 작성이나 은행 거래, 이미지 분류등의 다양한 작업을 할 수 있다는 것이다. 이러한 작업이 가능한 이유는 CPU는 폰 노이만 구조를 따르기 때문이라고 한다. 하지만 CPU의 ALU는 한 번에 하나의 계산만 실행할 수 있어 병목현상이 발생된다고 한다. 위의 그림을 통해 이해해보면, 9차원 짜리 입력 데이터가 들어왔을때 각 차원에 가중치를 곱하는 작업을 한 번에 하나씩 진행하는 것 같다.
예전에 마이크로프로세서 수업을 들을때 외웠던 용어 같은데 생각이 안 난다..
ALU: 두 숫자의 산술 연산(+,-,$\times$, $\div$)과 비트 연산(NOT, AND, OR, XOR)을 수행하는 디지털 회로이며 곱셈기(multiplier)와 가산기(adder)를 포함하고 있다.
1.1.2. GPU 작동 원리
 gpu 작동 원리
gpu 작동 원리
GPU는 단일 프로세서에 다량의 ALU를 배치하여 CPU에 비해 높은 처리량을 얻는 방법을 사용한다고 한다. 단순하게 생각하면 ALU를 많이 넣어서 산술, 논리 계산을 한 번에 많이 할 수 있도록 만든 것 같다. 마찬가지로 위의 그림을 통해 이해해보면, 9차원 짜리 입력 데이터가 들어왔을때 각 ALU에서 수행하는 작업은 CPU와 동일하지만 이러한 ALU를 여러개 사용함으로써 한 번에 많은 데이터를 처리할 수 있는 것 같다. 이러한 GPU의 경우 신경망의 행렬 곱셈과 같은 대규모 병렬처리에 적합하지만, GPU 또한 범용성을 지닌 프로세서로 CPU와 마찬가지로 병목현상을 가진다고 한다. 그리고 수천 개의 ALU에서 병렬적으로 연산을 수행하기 때문에 그에 비례하여 더 많은 에너지를 소비하기 때문에 하드웨어적인 부담이 가중된다고 한다.
1.1.3. TPU 작동 원리
TPU는 Google이 딥러닝 학습에 특화되게 만든 행렬 프로세서이다. 이세돌 바둑기사와 대국을 했던 알파고 Lee 버전에서는 48개의 TPU를 사용했다고 하고 알파고를 이긴 알파고 제로는 4개의 TPU를 사용하여 학습을 했다고 하니 나온지 얼마 되지는 않았지만 TPU 성능이 점점 발전하고 있는 것 같다. 알파고 제로의 모델이 조금 더 최적화된 이유도 있겠지만
Google에서는 이러한 TPU의 가장 큰 장점으로 CPU, GPU에 비해 폰 노이만 병목현상이 적다고 이야기하고 있다.

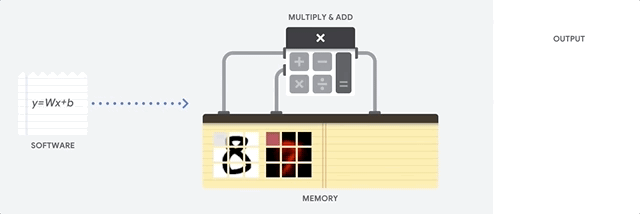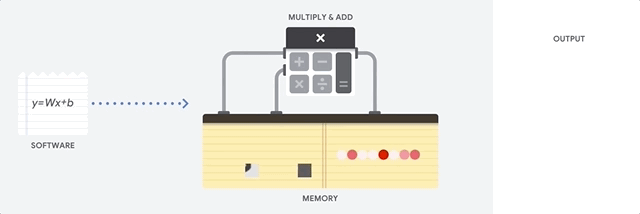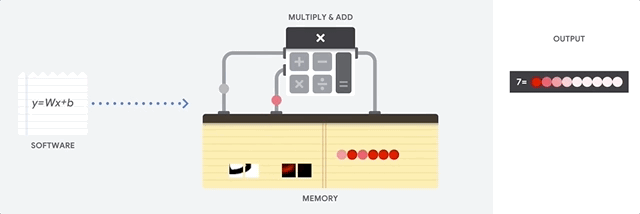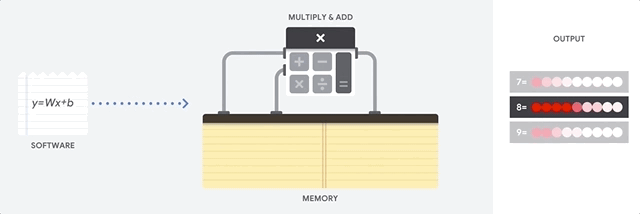
TPU의 작동을 살펴보면 우선 모델의 parameter(가중치)를 곱셈기와 가산기에 로드한다고 한다. 위의 그림을 보면 5,6,7,8,9에 해당하는 parameter를 ALU에 로드한다. 따라서 그림의 첫 번째(제일 위) 행은 9에 해당하는 parameter를 가지고 있고, 다섯 번째(제일 아래) 행은 5에 대한 parameter를 가지고 있다.
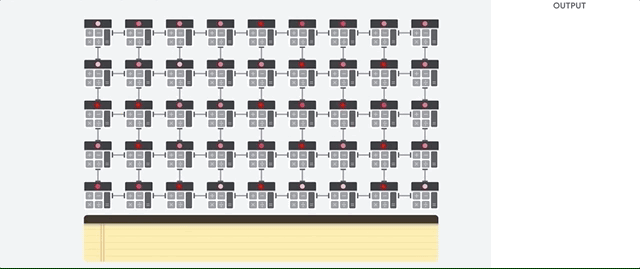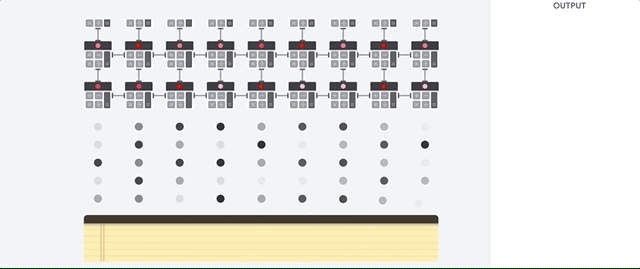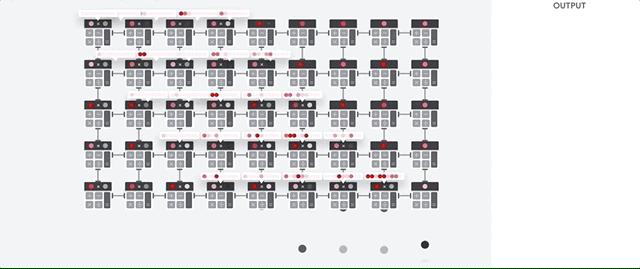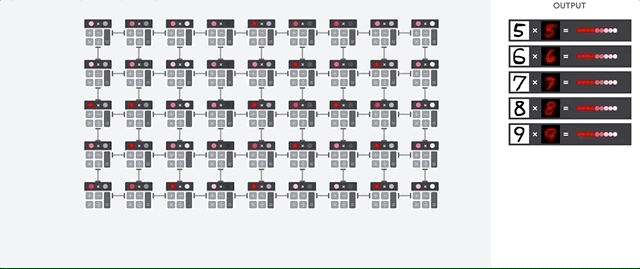
그 다음으로 TPU가 메모리에서 입력 데이터를 로드하고 입력으로 넣어주면 다섯 번째 행에서 5에 대해 계산을 하고 계산된 데이터는 네 번째 행으로 이동하여 6에 대해 계산한다. 다섯 번째 행에서 계산된 데이터가 네 번째 행으로 이동함과 동시에 새로운 데이터가 다섯 번째 행으로 입력되는 과정을 반복하여 모든 입력 데이터에 대해 수행을 한다. 이러한 과정에서 메모리 엑세스가 필요하지 않아 높은 연산 처리량을 보여주는 동시에 하드웨어 부담을 줄였다고 한다.
2. Colab에서 Single-core TPU 사용하기
TPU에 대해 간단히 알아봤으니 이제 실제로 TPU를 사용해보자. TPU를 사용하기 위해선 당연힉 구글 계정이 필요하다. TPU는 Google Gloud Platform이나 colab에서 사용이 가능한 것 같다. GCP는 AWS처럼 돈을 내고 사용이 가능한 것으로 알고 있기 때문에 나는 colab을 이용하여 TPU를 사용하려 한다. 그리고 예전에는 딥러닝 프레임워크로 TensorFlow를 많이 사용했었는데, 최근에 박사과정을 시작하면서 PyTorch로 옮겨오게 되면서 본 포스팅에서도 PyTorch를 이용하여 TPU에서 실행시켜보려고 한다.
2.1. XLA 라이브러리
TPU는 구글이 만들어서 제공하고 있기 때문에 아무래도 마찬가지로 구글에서 만든 TensorFlow에서 사용하게 만들어진 것 같다. 하지만 최근 딥러닝 연구가 모든 것을 오픈하고 공유하는 추세인지라 PyTorch에서도 TPU 사용이 가능하도록 라이브러리를 제공하고 있다. XLA(Accelerated Linear Algebra)는 선형 대수 계산에 최적화된 컴파일러로 TensorFlow 모델 가속화를 위해 구글에서 만든 것 같다. 그리고 구글에서 만든 이 XLA 라이브러리를 PyTorch에서 사용하기 위해 PyTorch용 XLA인 PyTorch/XLA를 사용하면 된다. PyTorch용 xla는 어디서 만든거지? 구글에서 만든건가?
2.2. MNIST 예제를 single-core TPU에서 실행해보자
PyTorch/XLA를 이용하기 위해 해당 Github에 있는 TPU 사용 예제와 PyTorch의 기본 예제인 MNIST 예제를 이용하여 사용해보려고 한다. 본 포스팅에서의 모든 코드는 colab에서 실행하는 것을 기본으로 한다.
예제를 돌리기 전에 colab에서 TPU를 잡을수 있도록 세팅하도록 하자. colab에서 .ipynb 파일을 하나 띄워두고 Edit > Notebook settings에서 Hardware accelerator를 TPU로 선택하자.
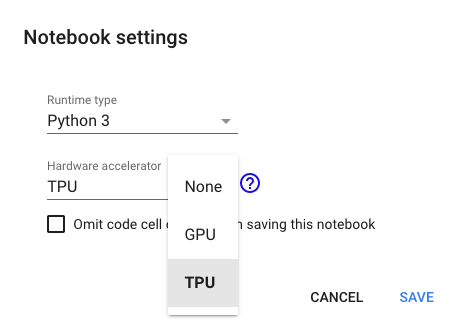
TPU 세팅을 완료했다면 colab에 PyTorch/XLA를 설치하자.
import os
assert os.environ['COLAB_TPU_ADDR'], 'Make sure to select TPU from Edit > Notebook settings > Hardware accelerator'
VERSION = "20200220"# or "xrt==1.15.0"
!curl https://raw.githubusercontent.com/pytorch/xla/master/contrib/scripts/env-setup.py -o pytorch-xla-env-setup.py
!python pytorch-xla-env-setup.py --version $VERSION
TPU가 제대로 잡혔다면 위의 코드를 실행했을 때, 오류가 뜨지 않을 것이다. VERSION의 경우 현재(2020-02-27) 기준으로 세 가지가 있는 것 같다.
- 20200220
- nightly
- xrt==1.15.0
각 버전이 무슨 차이인지는 정확히 모르겠지만, 나중에 TPU를 multi-core로 돌리기 위해선 xrt==1.15.0을 설치하도록 하자. 20200220 버전의 경우 single-core에서는 잘 작동하는데 multi-core에서는 오류가 발생하는 것으로 확인하였다.20200220 버전도 multi-core에서 오류가 발생하지 않는다 xrt==1.15.0과 20200220 버전 중 아무거나 설치해도 괜찮을 듯 하다. (nightly 버전은 거의 사용을 안 하는 듯 하다.)
PyTorch/XLA가 설치되었다면 이제 코드를 세 부분만 수정하면 TPU에서 실행이 가능하다. 본 포스팅에서는 MNIST 예제를 TPU에서 실행하기 위해 수정이 필요한 부분만 작성하도록 한다.
1. PyTorch/XLA 라이브러리를 import한다.
# imports the torch_xla package
import torch_xla
import torch_xla.core.xla_model as xm
2. 모델을 TPU에 올린다.
TPU에 모델을 올리는 방법은 GPU와 크게 다르지 않다.
device = xm.xla_device()
model = Net().to(device)
GPU에서와 같이 위의 코드를 통해 모델을 device에 올려주자.
3. optimzer의 step을 xla 라이브러리를 이용하자
optimizer.zero_grad()
loss.backward()
xm.optimizer_step(optimizer, barrier=True)
기존의 optimizer.step()을 xm.optimizerz_step(optimizer, barrier=True)로 변경해주자.
위의 세 가지만 수정해주면 GPU나 CPU에서 돌리던 MNIST 예제를 TPU에서 돌릴 수 있다. 다음 포스팅에서는 MNIST 예제를 multi-core TPU에서 돌리는 것을 정리해보도록 하겠다.
참고자료
- Google TPU 가이드 https://cloud.google.com/tpu/docs/beginners-guide?hl=ko
Leave a comment